;)

;)
;)

;)
;)
;)

;)
;)
;)
;)
;)
;)
;)

;)
;)
;)
;)
;)
;)
;)
;)
;)
;)
;)
;)

Problem Description
Nagios Log Server is in a red health state. You can see the current cluster state by navigating to (Administration -> Cluster Status):
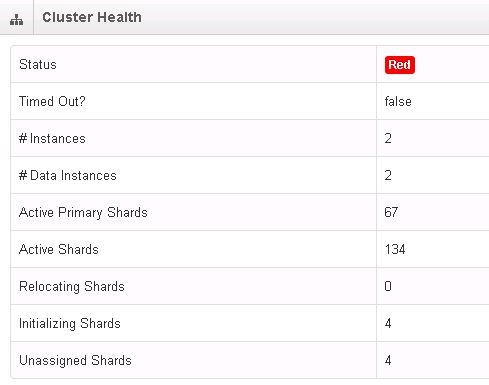
The cluster can be in one of three states:
Green: All primary and replica shards are active and assigned to instances.
Yellow: All data is available but some replicas are not yet allocated (cluster is fully functional).
Red: There is at least one primary shard that is not active and allocated to an instance (cluster is still partially functional).
The cluster health is controlled by the worst index status. The index status is controlled by the worst shard status in that index.
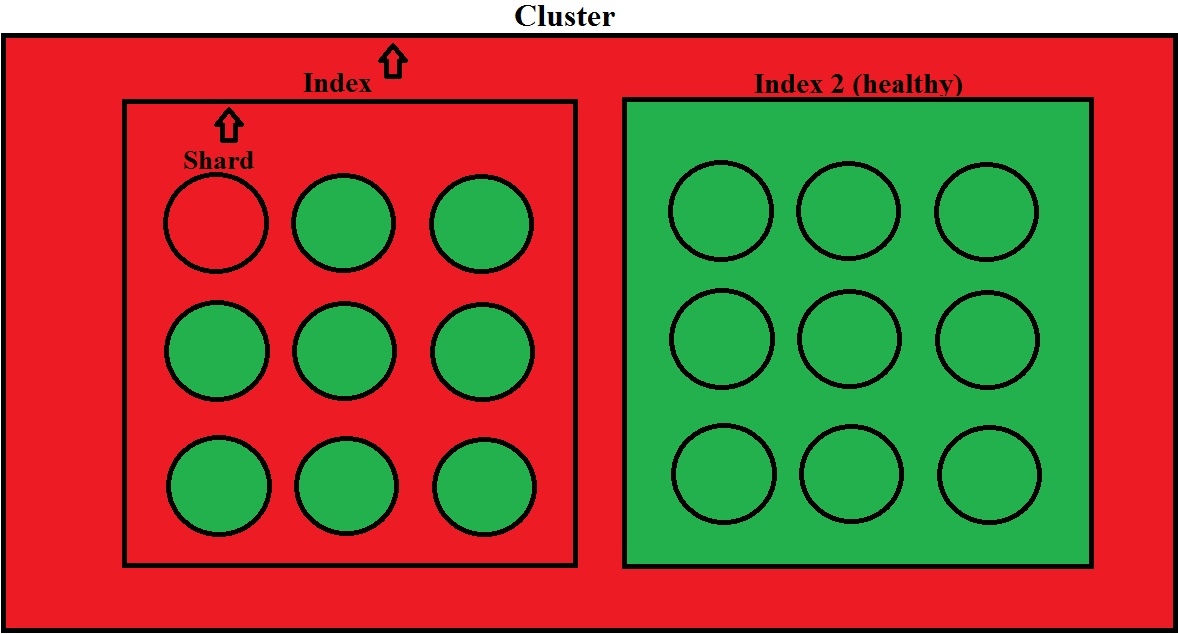
The cluster health status is controlled by the least healthy index in the cluster.
Potential Causes
What can cause a shard to become unassigned/corrupt?
-
Unexpected reboots or shutdowns - an unexpected reboot or shutdown of any instance in your cluster can cause a primary shard to become detached or corrupt. In most cases, Elasticsearch will recover from this problem on its own.
-
Port 9300 is closed - ensure that Port 9300 is open on all clustered servers.
CentOS Example:sudo firewall-cmd --zone=public --permanent --add-port=9300/tcp
sudo firewall-cmd --reload -
Disk space fills up - if Nagios Log Server runs out of disk space, serious complications can occur. Typically this results in corrupt/unassigned shards.
Note: Disk space will need to be increased, or existing Log Server data will need to be removed.
-
Out of memory error - if Elasticsearch takes up too much system memory, the kernel could reap Elasticsearch. You will see an explicit message in /var/log/messages at the time this occurs. The sudden reaping of Elasticsearch could cause corrupt/unassigned shards.
Note: Memory will likely need to be increased on Nagios Log Server before restart - otherwise you risk Elasticsearch being reaped again.
Troubleshooting
Now that we know what can cause this issue, let's get your cluster back to a green state. The very first thing you should do is to secure your backups, if you have any. Next, run the following commands from any instance on the cluster:
cluster health:
curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
shard status:
curl -XGET 'http://localhost:9200/_cat/shards?v'
Cluster health should return a result similar to this:
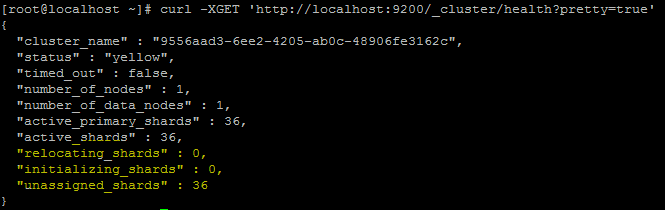
Note the fields that I have highlighted. If a shard is unassigned or initializing, it is not healthy.
From here you can identify which types of shards might be missing. From the above, we can deduce that the 36 assigned shards (active_shards) are primary shards. That must mean that the 36 unassigned_shards are replica shards. This would explain why my health status is yellow.
If you see a high amount of unassigned_shards and initializing_shards, please run the health command once in awhile to see if the number goes down - sometimes Elasticsearch fixes itself. If the number stays the same for an extended period, you could try rebooting your instances one at a time. If you are still seeing problems, please proceed to Shard Status.
Shard Status should return a result similar to this:
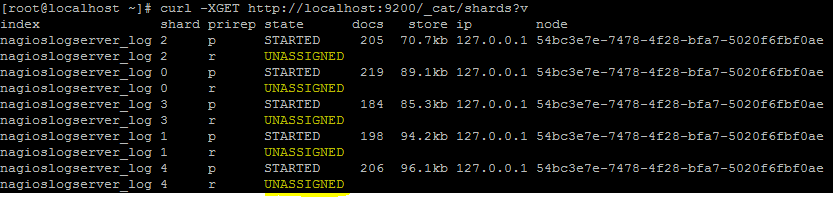
Note the highlighted fields. Anything INITIALIZING or UNASSIGNED is a red flag. From here, you can see which index the unassigned shards belong to. You can also see whether they are ![]() rimary or
rimary or ![]() eplica shards. You can get a list of all potential problem shards with the following command:
eplica shards. You can get a list of all potential problem shards with the following command:
Type:
curl -s -XGET http://localhost:9200/_cat/shards?v | egrep 'UNASSIGNED|INITIALIZING'
You can choose one of two procedures:
IMPORTANT: If possible, use option 1 - deleting and restoring the indices requires that you have a working backup in place, and that the offending index was backed up prior to the incident. If you decide to use option 2, please proceed at your own risk - I have seen the re-assignment process kill elasticsearch, which could cause more problems.
-
Delete the offending indices, and restore those indices from your backup. A working backup is required for this to be possible. Check your backups by navigating to (Administration -> Backup & Maintenance).
Index deletion command:
curl -XDELETE 'http://localhost:9200/indexnamehere/'
Example:
curl -XDELETE 'http://localhost:9200/logstash-2016.02.25/'
-
Attempt to re-assign the shards.
Re-assignment command:
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{ "commands" : [ { "allocate" : { "index" : "indexnamehere", "shard" : shardnumberhere, "node" : "nodenamehere", "allow_primary" : true } } ] }'Using the screenshot above, here is a full example:
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{ "commands" : [ { "allocate" : { "index" : "nagioslogserver_log", "shard" : 2, "node" : "54bc3e7e-7478-4f28-bfa7-5020f6fbf0ae", "allow_primary" : true } } ] }'
Final Thoughts
For any support related questions please visit the Nagios Support Forums at:


